Eksperimen Komputasi Sastra
Pembacaan Jauh atas 29 Novel Pemenang Sayembara DKJ 1998–2021

Bagaimana hasilnya jika artificial intelligence menganalisis novel pemenang sayembara DKJ selama dua dekade ke belakang? Sebagai gambaran sederhana, sebelum menjelaskan secara rinci eksperimen ini, saya sempat mencoba menggunakan Chat GPT-4 untuk menjawab pertanyaan itu. Saya meminta ia membuat tiga klaster topik dari korpus novel pemenang sejak 1998-2021. Hasilnya, bagi saya, tidak begitu memuaskan. Meski sudah mengingatkan ke robot chat bahwa korpus tersebut berbahasa Indonesia, dan sudah memerintahkan untuk menghapus frekuensi kata dominan yang berasal dari kelas kata preposisi, konjungsi, atau pronomina, sebab tidak memberi makna substantif, tetap saja ChatGPT-4 mengelompokkan frekuensi dari kata-kata tersebut dan memberi interpretasi atas tiga topik dominan sebagai berikut: 1) Topik pertama tampaknya berkisar pada hubungan pribadi dan sosial, dengan fokus pada orang, tindakan mereka, dan lingkungan seperti rumah; 2) Topik kedua tampaknya berkaitan dengan pengalaman dan refleksi individu, kemungkinan mengeksplorasi tema keberadaan, interaksi pribadi, dan keadaan emosionalnya; 3) Topik ketiga tampaknya berfokus pada hubungan dan pengalaman interpersonal, dengan penekanan pada perspektif kolektif serta kontras atau kontradiksinya.
Hasil interpretasi dari ketiga topik tersebut memang saling beririsan, semisal soal hubungan pribadi seseorang atau keberadaannya dalam suatu ruang serta keragamanan pengalaman sosial maupun reflektifnya. Kesamaan interpretasi itu muncul lantaran kata-kata utama acuan yang keluar dari ketiga pengelompokan (clustering) topik dari korpus itu relatif sama. Ini menjadi masalah sebab sejak awal saya ingin memetakan topik dominan untuk mendapatkan gambaran atau pola umum yang mungkin luput dari pembacaan pengindraan manusia biasa. Pangkal soalnya adalah bahwa analisis menggunakan mesin ini hanya dapat memberikan wawasan yang berarti jika mesin memahami kebutuhan yang diperlukan dari setumpuk data besar itu.
Mengingat bahwa korpus yang akan dianalisis merupakan teks, yang dalam pengertian ini didefinisikan sebagai data tidak terstruktur, kehadiran saya sebagai manusia dalam mengevaluasi hasil pembacaan mesin (human-in-the-loop) untuk memeriksa tetap menjadi penting. Oleh karena itu, ketidakpuasan menggunakan Chat GPT-4 dari OpenAI kemudian mendorong saya untuk mencoba merangkai kode pemrograman AI sendiri.
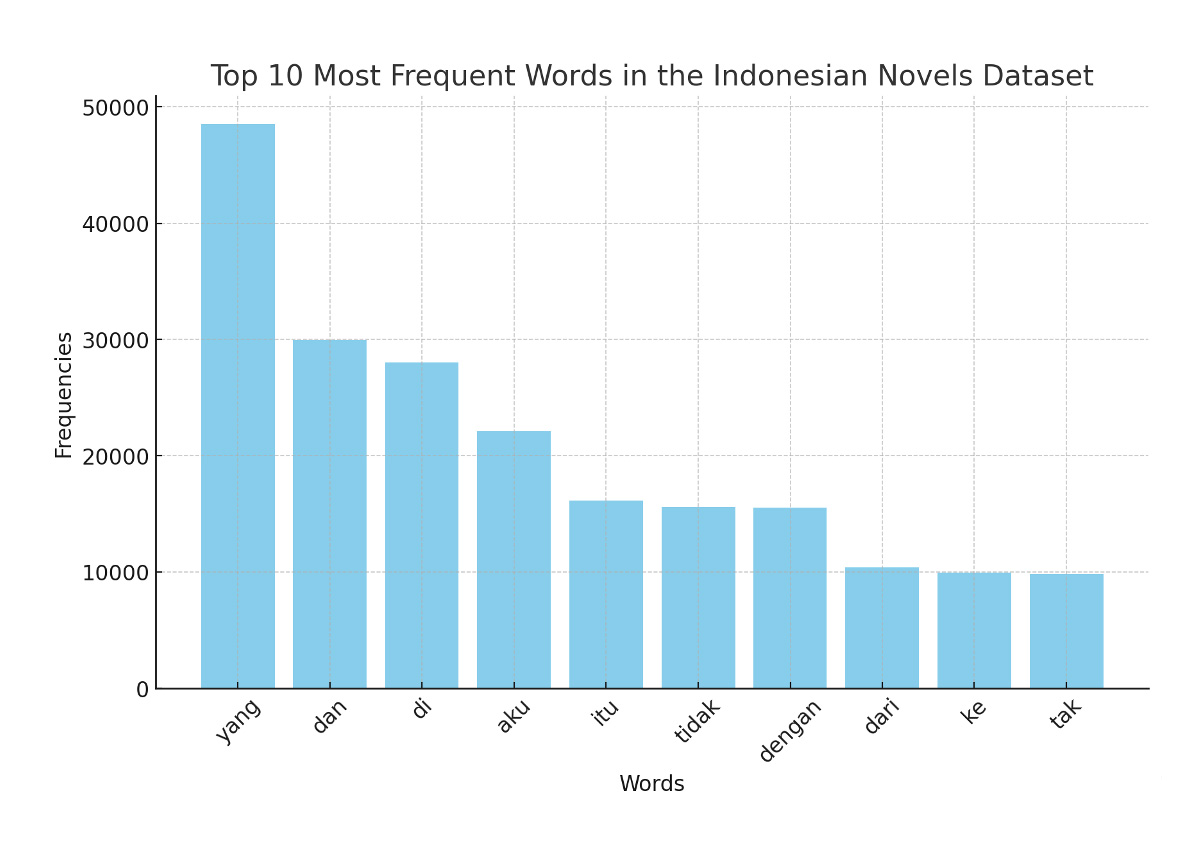
Kata-kata dengan frekuensi kemunculan paling sering di atas adalah landasan dasar interpretasi yang disajikan GPT-4 ketika membaca 29 para pemenang novel DKJ yang dipilih secara acak sejak tahun 1998. Tentu, meski unsur-unsur kata tersebut berguna sebagai perangkat naratif sebuah teks, tetapi ia tidak menggambarkan apa saja yang saling berkaitan dalam teks, yang polanya tidak terbaca secara kasat mata. Bandingkan misalnya dengan grafik batang frekuensi kata di bawah ini, yang telah dibersihkan dari kata-kata di atas:
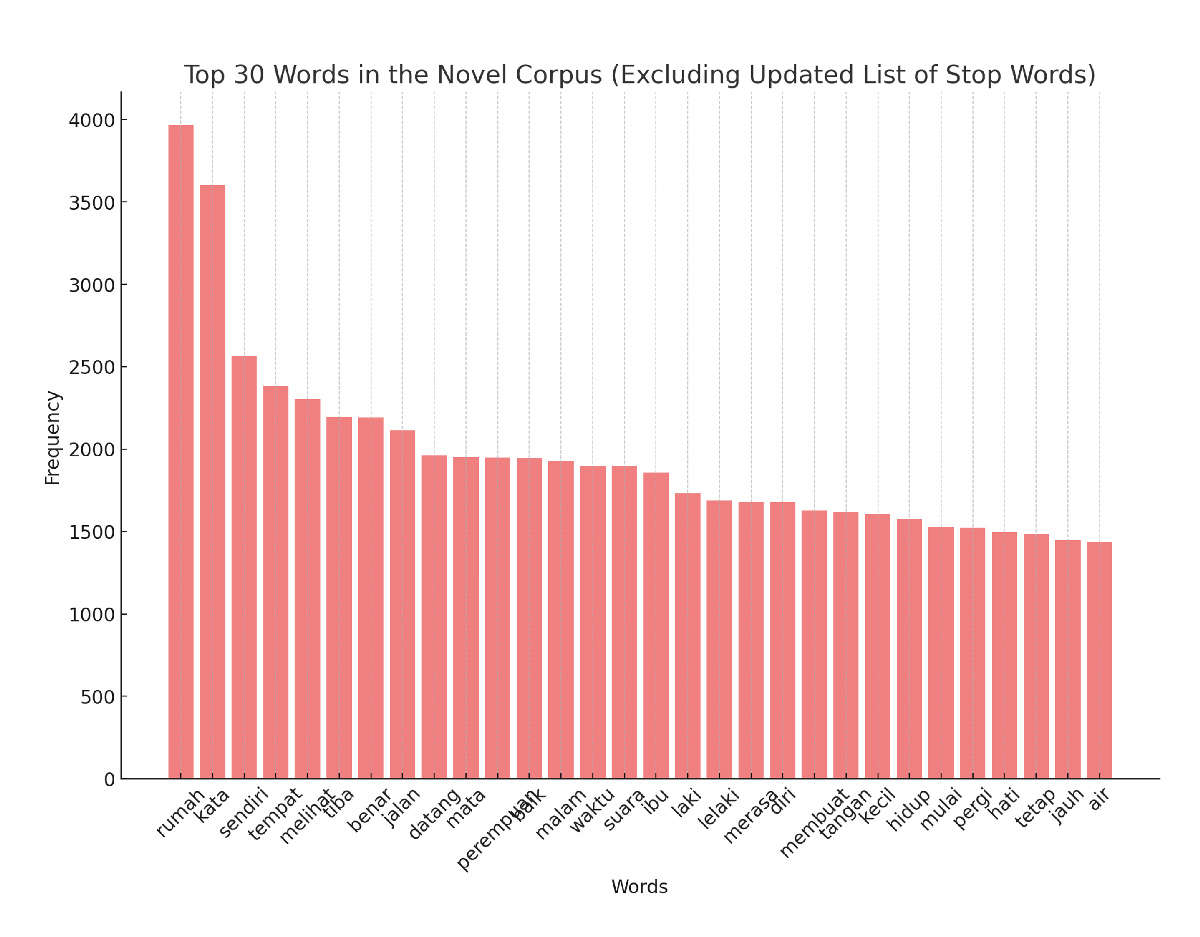
Grafik di atas menunjukkan kata-kata dengan frekuensi kemunculan paling tinggi. Akan tetapi, ia tidak cukup menjelaskan keterkaitan setiap kata dengan kata yang lain sehingga menunjukkan suatu jalinan tematik. Berangkat dari tujuan untuk membaca pola umum dari sekian teks DKJ, maka dalam analisis ini saya memanfaatkan pemrosesan bahasa alami (natural language processing), yakni Latent Dirichlet Allocation (LDA) yang tergolong sebagai metode statistik generatif.
Penerapan Pembelajaran Mesin dalam Analisis Sastra
Seiring berkembangnya tren humaniora digital, Latent Dirichlet Allocation (LDA) adalah salah satu model statistik yang semakin banyak digunakan dalam kajian komputasi sastra, khususnya untuk mengeksplorasi tema-tema dalam kumpulan teks besar.[1] Kajian komputasi sastra tidak sejalan dengan metode hermeneutik yang memayungi metode interpretasi dan penjelasan atas sebuah teks.[2] Metode ini, tentu saja, tidak bertujuan merekonstruksi kembali makna yang direpresentasikan oleh teks. Kajian komputasi sastra, dengan demikian, mencoba mencari kemungkinan interpretasi lain yang justru tidak datang dari disiplin pembacaan formal.
Penerapan teknik komputasional dalam kajian sastra, yang juga sering disebut pembacaan jauh (distant reading), dianggap menggantikan pembacaan dekat atau metode konvensional yang memeriksa teks dengan cermat. Anggapan tersebut berangkat dari pengertian bahwa mesin atau kecerdasan buatan akan menggantikan peran manusia yang menganalisis karya sastra. Meski beberapa percobaan serupa terbilang tidak sedikit, tetapi artikel maupun eksplorasi tersebut seringkali datang dari wilayah ilmu komputer “murni” yang memang bertujuan untuk mengembangkan AI atau Large Language Model. Sedangkan kajian komputasi sastra lebih menekankan bagaimana kecerdasan buatan dapat membantu kritikus sastra memetakan korpus gigantis dalam waktu singkat. Perdebatan mana yang lebih baik akan terasa sia-sia belaka. Sebab ilmu komputer dan sastra bersifat bukan saling menggantikan, melainkan saling melengkapi. Dalam kajian sastra, pemodelan topik berguna jika prosesnya dijalankan dengan hati-hati dan dengan konteks pengetesan statistik yang dapat terukur hasilnya.
Dalam lingkup akademis, para peneliti menerapkan LDA untuk mengungkap serta menganalisis struktur tematik karya sastra. Pendekatan ini dapat menampilkan persamaan atau perbedaan mendasar dalam tema, bahkan di antara novel-novel yang awalnya tampak tidak berhubungan. Sampai batas tertentu, LDA juga memungkinkan eksplorasi tren tematik di berbagai genre, penulis, atau periode sejarah. LDA beroperasi dengan prinsip bahwa setiap novel merupakan campuran dari berbagai topik. Suatu topik dapat dipahami sebagai sekelompok kata yang sering muncul bersamaan. Hal ini dilakukan dengan mengevaluasi seberapa sering sebuah kata muncul dalam suatu topik dan seberapa dominan setiap topik dalam sebuah novel. Melalui beberapa kali pengulangan, proses ini menghasilkan pengelompokan kata ke dalam topik yang lebih stabil dan bermakna.
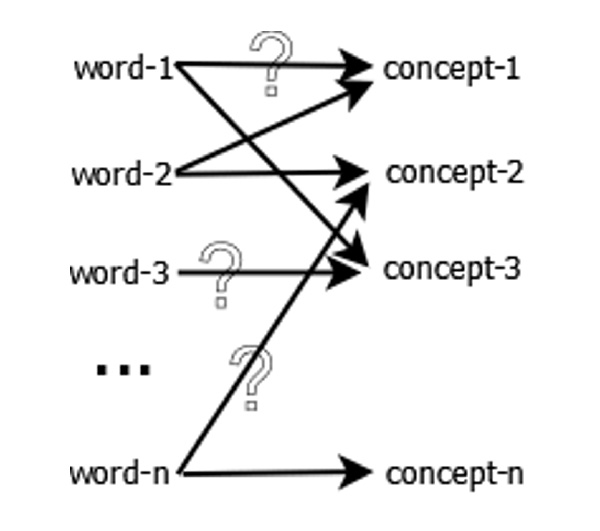
Mengingat ia tergolong pada soft clustering, maka setiap kata bisa masuk ke dalam beberapa pengelompokan yang di dalamnya berhimpun kata-kata lain yang sering muncul bersamaan seperti tergambar dalam ilustrasi di bawah ini:
Pada tahapan awal, proses utama dalam eksperimen ini adalah menyiapkan teks dari novel-novel tersebut. Langkah ini melibatkan pemecahan teks menjadi kata-kata individual (tokenisasi), menghilangkan kata-kata umum yang tidak substantif (kata penghenti/stopwords), dan mengubah kata-kata menjadi bentuk akarnya (stemming dan lemmatization). Persiapan ini penting untuk memastikan bahwa analisis berfokus pada isi novel yang bermakna.
Pemrosesan LDA akan secara acak menetapkan kata-kata dalam novel ke sejumlah topik tertentu. Namun, keacakan ini hanyalah titik awal. Inti penerapan LDA dalam analisis sastra terletak pada penafsiran topik-topik tersebut. Setiap topik, sebagai kumpulan kata, menunjukkan elemen tematik yang mendasari novel. Menafsirkan topik-topik ini memerlukan keseimbangan yang cermat antara analisis statistik dan pemahaman kontekstual. Namun, terdapat tantangan dalam menggunakan LDA untuk analisis sastra. Penafsiran topik bisa bersifat subjektif. Oleh karena itu, memutuskan jumlah topik yang akan digunakan dalam model sangatlah penting dan dapat berdampak signifikan terhadap analisis. Selain itu, LDA tidak memperhitungkan gaya narasi atau urutan kata, yang mungkin penting dalam konteks analisis karya sastra. Dengan demikian, LDA dapat memberikan gambaran yang berguna untuk analis tematologi, tetapi tidak memberikan sumbangsih terhadap naratologi.
Ringkasnya, penerapan LDA pada analisis novel sastra menawarkan perspektif baru dalam kajian sastra. Ini menggabungkan metode komputasi dengan pendekatan analitis tradisional, memberikan wawasan lebih dalam tentang isi tematik sastra. Pendekatan ini mewakili langkah signifikan dalam evolusi analisis sastra, memanfaatkan metode berbasis data untuk meningkatkan pemahaman kita tentang kemungkinan lain yang dapat muncul dari analisis sastra.
Pra-pemrosesan Data
Proses paling menantang dari analisis ini adalah menyiapkan korpus teks. Pada mulanya, analisis ini berusaha untuk memetakan seluruh novel pemenang Sayembara DKJ sejak pertama kali diadakan pada 1974. Akan tetapi, mengumpulkan setiap judul yang merentang dalam setengah abad adalah sebuah pekerjaan yang cukup melelahkan. Dengan bantuan pinjaman judul dari beberapa kawan serta arsip novel yang disimpan oleh DKJ,[3] eksperimen pembacaan jauh ini memilih novel-novel yang berasal dari periode 1998-2021. Meski relatif mudah ditemukan, lantaran jarak tahun terbitnya tidak terlalu jauh, tetap saja beberapa judul begitu sukar untuk didapatkan. Tenggat yang pendek dalam pengerjaan membuat saya pada akhirnya berusaha mengolah dari data yang berhasil dikumpulkan secara kolektif. Daftar di bawah ini adalah judul-judul yang menjadi korpus utama eksperimen pembacaan jauh ini:
| 1 | 1998 | Ayu Utami | Saman |
| 2 | 1999 | Taufik Ikram Jamil | Hempasan Gelombang |
| 3 | 2000 | Ediruslan | Dikalahkan Sang Sapurba |
| 4 | 2004 | Abidah | Geni Jora |
| 5 | 2004 | Dewi Sartika | Dadaisme |
| 6 | 2004 | Ratih Kumala | Tabula Rasa |
| 7 | 2007 | Calvin | Jukstaposisi |
| 8 | 2007 | Junaedi Setiono | Glonggong |
| 9 | 2008 | Turisan Suseno | Mutiara Karam |
| 10 | 2008 | Yonathan Rahardjo | Lanang |
| 11 | 2009 | Anindita | Tanah Tabu |
| 12 | 2011 | Arafat Nur | Lampuki |
| 13 | 2012 | Ramayda Akmal | Jatisaba |
| 14 | 2013 | Andina Dwifatma | Semusim dan Semusim Lagi |
| 15 | 2013 | Dewi Kharisma Michellia | Surat Panjang Tentang Jarak Kita yang Jutaan Tahun Cahaya |
| 16 | 2013 | Erni Aladjai | Kei |
| 17 | 2013 | Wisran Hadi | Persiden |
| 18 | 2014 | Junaedi Setiyono | Dasamuka |
| 19 | 2014 | Ziggy | Di Tanah Lada |
| 20 | 2015 | Bagus Dwi Hananto | Napas Mayat |
| 21 | 2015 | Faisal Odang | Puya ke Puya |
| 22 | 2015 | Mahfud Ikhwan | Kambing dan Hujan |
| 23 | 2016 | Arafat Nur | Tanah Surga Merah |
| 24 | 2017 | Sabda Armandio | 24 Jam Bersama Gaspar |
| 25 | 2017 | Ziggy | Semua Ikan di Langit |
| 26 | 2019 | Ahmad Mustafa | Anak Gembala yang Tertidur Panjang di Akhir Zaman |
| 27 | 2019 | Mochamad Nasrullah | Balada Supri |
| 28 | 2022 | Zaky Yamani | Kerata Semar Lembu |
| 29 | 2023 | Amalia Yunus | Bagaimana Cara Menangani Berat Badan |
Pemanfaatan AI sudah dilakukan sejak awal pra-pemrosesan. Proses otomatisasi awal menggunakan perangkat lunak dari alat pemindai. AI mengubah gambar menjadi teks. Hasil dari pemindaian tersebut tidak serta merta dapat langsung diolah, tetapi perlu dibersihkan terlebih dulu. Selazimnya, pada pra-pemrosesan setiap saltik serta galat dari pemindaian AI alias OCR perlu diperiksa satu per satu. Problem utama yang dihadapi Chat GPT-4 dalam menjalankan tugas interpretasi yang diberikan, seperti yang disebut di muka, ialah tidak mengenali korpus tersebut sebagai bahasa Indonesia. Oleh karena itu, dalam rakitan kode yang saya susun, saya memanfaatkan modul sastrawi agar mesin mengenalinya. Selain itu, analisis ini memakai modul-modul lain yang lazimnya dipakai dalam penambangan data maupun pemrosesan bahasa alamiah dalam ekosistem bahasa pemrograman Python, antara lain gensim, spacy, nltk (natural language toolkit), dll.
Sebelum mengurai lebih jauh, ada beberapa istilah yang perlu dipahami bersama untuk tahapan pra-olah data, antara lain ‘token’, ‘korpus’ (yang telah disebut sejak awal), dan ‘kata penghenti’ (stopword). Token merupakan sebuah kata tunggal dalam format string. Jika merujuk korpus, maka yang dimaksud adalah serangkaian “bentuk” dokumen yang akan dianalisis. Sedangkan “kata penghenti” merupakan kata-kata umum yang biasa kita pakai dan jumpai, tetapi tidak berpengaruh sama sekali terhadap makna pembelajaran mesin yang diterapkan dalam analisis ini. Ada tiga tahapan pra-promesan dalam analisis ini, 1) tokenisasi, (tokenizing), 2) menentukan kata penghenti (stop words), 3) normalisasi.
Pada tahapan pertama, mesin menjalankan tokenisasi atas kata dalam korpus untuk menghapus karakter yang tidak penting dari teks, semisal pungtuasi, enjambemen, karakter emotikon, maupun karakter lain seperti angka, sebutan, tautan, dan tagar. Dengan kata lain, proses tokenisasi adalah proses mengidentifikasi simbol yang dapat dipahami komputer untuk mengenali kata sebagai unit analisis. Analisis ini, dengan demikian, kehilangan keterbacaannya secara gramatikal dan yang akan kita dapatkan dalam pembacaan jauh seperti ini ialah keterbacaan oleh mesin.
Sedangkan pada tahapan kedua, penentuan kata penghenti berdasarkan dari sejumlah frekuensi kata yang dibuang dalam analisis, seperti yang disebut sebelumnya. Tahapan ini bisa dilakukan secara semi-manual maupun otomatisasi penuh. Saya memilih manual, menginput satu per satu kata penghenti, bahkan juga membuang kata-kata dari kelas adjektiva maupun verba yang menduduki frekuensi teratas. Namun, pada tingkatan tertentu, saya sengaja membiarkan kata sifat maupun kata kerja yang saya anggap berhubungan dengan frekuensi kata dominan dalam suatu kelompok. Pembiaran terhadap frekuensi kemunculan kedua kelas kata itu, sampai batas tertentu, dapat membantu interpretasi mengenai pembacaan tema utama. Dalam hal inilah, sebagai pemodelan topik dalam pembelajaran mesin (machine learning), LDA seolah seperti proses artistik yang melampaui kemampuannya sebagai model matematika. LDA menjadi alat eksplorasi untuk mengolah data teks, mengungkapkan tema dan pola tersembunyi seperti seniman yang mengungkapkan visinya melalui karya. Menentukan kata henti dalam hal ini akan turut membentuk distribusi kata-kata dalam setiap “palet” atau pengelompokan.
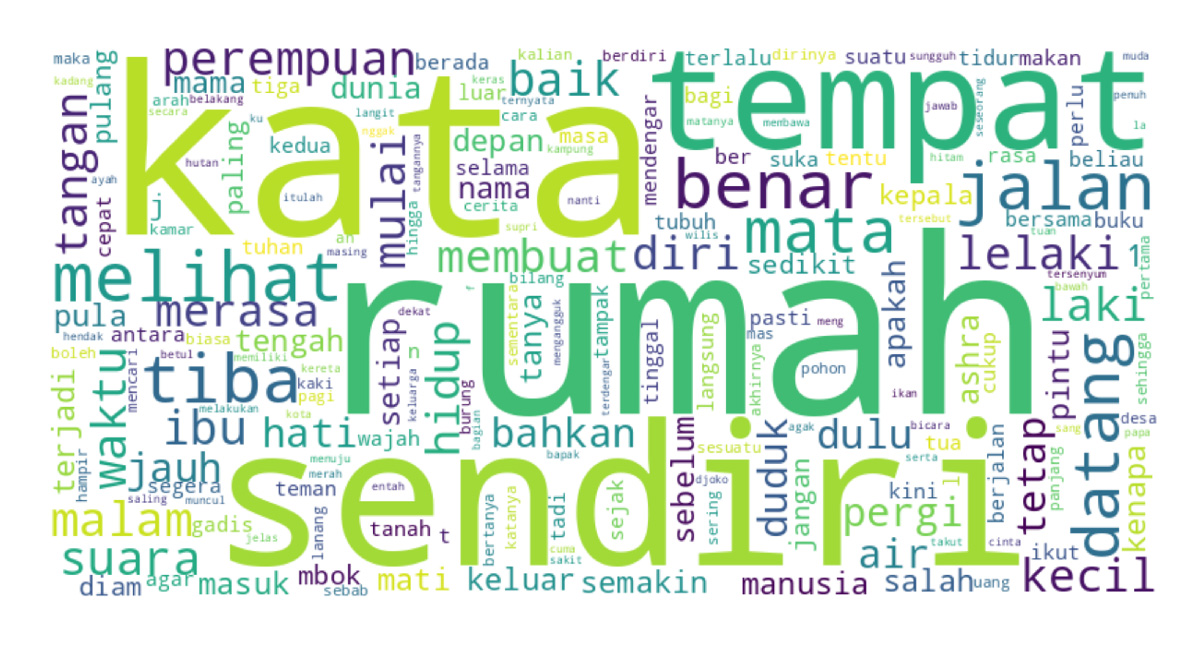
Terakhir, dalam proses normalisasi setiap kata akan disesuaikan selingkung maupun ejaannya. Sama seperti proses sebelumnya, dalam proses ini juga dapat dilakukan secara semi-manual, dengan menginput daftar kata yang akan dinormalisasi, atau mengandalkan sepenuhnya modul stemmer, yang menghilangkan afiksasi setiap kata dan mengembalikan ke bentuk kata dasarnya. Proses inilah yang memakan waktu paling lama, mengingat jumlah kata yang perlu diproses jumlahnya 1.512.659 kata. Proses ini juga cukup krusial, sebab tahapan ini menjadi titik final identifikasi komputer terhadap setiap kata berbahasa Indonesia. Setelah proses stemming selesai, kita masih dapat menentukan kembali dan menambahkan kata penghenti. Di bawah ini, tersaji kata awan dari setiap kata dengan frekuensi paling tinggi dari dalam korpus 29 novel pemenang sayembara novel DKJ sejak 1998:
Membaca Visualisasi LDA
Jauh sebelum analisis final LDA dijalankan, saya setidaknya sudah melakukan 14 kali percobaan. Dalam proses ini saya beberapa kali menemui galat dan berhadapan dengan persoalan remeh tetapi akan menggagalkan semua pemrosesan, saltik alias salah ketik. Awalnya, saya mencanangkan banyak hipotesis untuk diuji dengan hasil pembacaan mesin. Semisal, hubungan sosial yang dibentuk oleh tema umum dominan serta produksi wacana dari ekosistem budayanya, dalam hal ini mengukur hubungan timbal balik produksi budaya. Akan tetapi, setelah menimbang keterbatasan waktu, saya hanya akan berfokus membicarakan mengenai hasil pembacaan LDA.
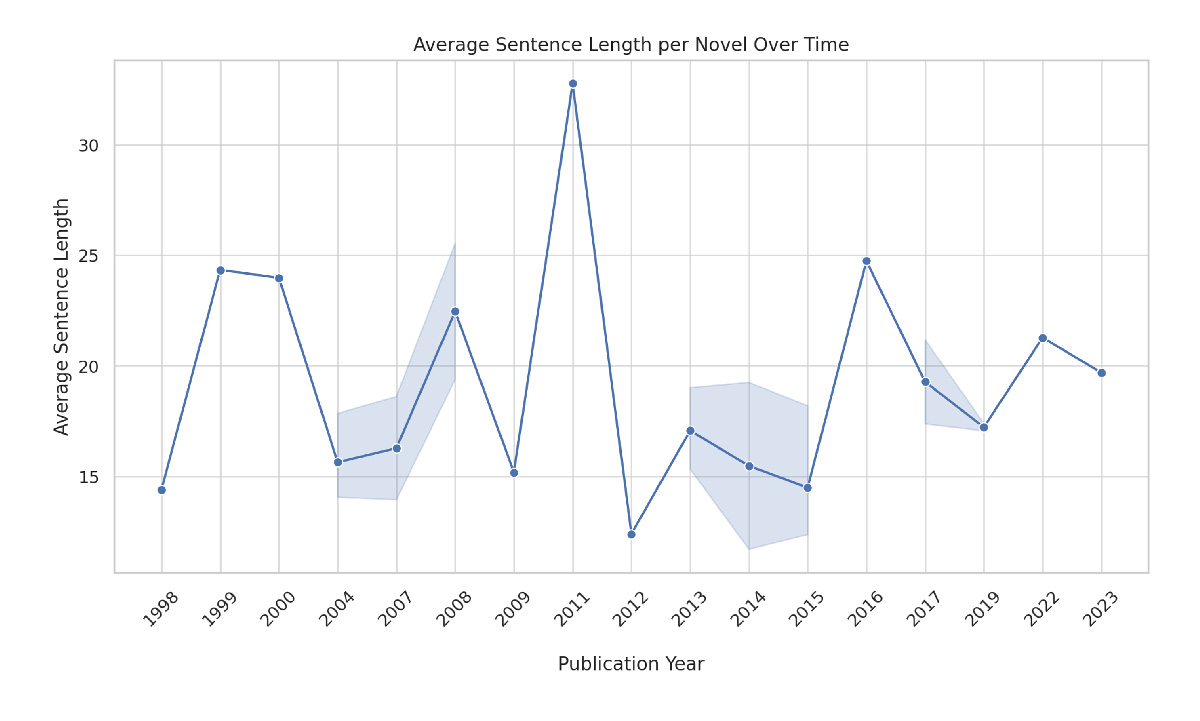
Sebelum menguraikan hasil pengolahan LDA, saya ingin membicarakan salah satu hipotesis yang ingin saya uji sebelumnya, yakni keberadaan tren yang membuat para penulis cenderung memilih kalimat yang lebih pendek, tidak mempertimbangkan lagi unjuk kemampuan merangkai kalimat sebagai laku utama, dan lebih memikirkan kemampuan fokus pembaca dalam menghadapi teks. Akan tetapi, rentang periode 25 tahun tidak cukup memberikan gambaran berarti soal hipotesis ini, yang ingin menyorot mengenai perubahan jumlah rata-rata kata dari suatu kalimat. Hasil awal dari pemrosesan data frekuensi kata setiap kalimat ini tidak menjelaskan dengan memuaskan kecurigaan awal tersebut. Mulanya, saya sempat memilih salah satu judul sampel secara acak untuk mengetahui rata-rata jumlah kata per kalimat. Angka yang keluar pun serupa dengan formula yang biasanya diajarkan dari kelas-kelas menulis, yakni 15 kata maksimal. Memang korpus dari sayembara novel DKJ tidak dapat menjawab kecurigaan awal saya tersebut, tetapi selama 2012 – 2015, misalnya, jumlah rata-rata kata dalam satu kalimat berada di bawah 15 sampai 17 kata. Dalam rentang periode itu memang media sosial dan budaya visual tengah meledak. Meski kedua konteks tersebut sulit dibuktikan keterhubungannya, tetapi dalam hal ini saya ingin mengetengahkan persoalan membaca suatu zaman atau periode sejarah dari frekuensi kata yang sering muncul, yang sering berada dalam satu pengelompokan tertentu, atau dari jaringan sosialnya. Dari sini terlihat bahwa hasil pembacaan mesin, meski terlepas dari konteksnya, akan memberikan gambaran lain dari suatu periode lewat pemodelan.
Pemilihan LDA visual interaktif dalam eksperimen ini bukan hanya untuk memberikan kemudahan operasional untuk melihat atau meninjau hasil analisis, melainkan juga untuk memahami bagaimana pemodelan topik ini dapat mengungkapkan pola umum dari korpus. Maka, pertama-tama penting untuk memahami bagaimana membaca dan menggunakan visualisasi interaktif ini. Di bawah ini tersaji visualisasi interaktif topik dengan LDA berbasis web yang menampilkan hasil pemrosesan dari keseluruhan pemenang sayembara novel DKJ 1998 – 2021.
Visual Interaktif LDA Novel Pemenang DKJ Periode 1998 – 2021
LDAvis ini di atas terdiri dari dua bagian: 1) diagram batang di sebelah kanan dan 2) peta jarak antar-topik di sebelah kiri.
Peta jarak antara setiap topik menggambarkan kedekatan antara setiap pengelompokan. Topik dengan kata-kata yang lebih tumpang tindih akan tampak berdekatan di peta ini. Dalam ruang dua dimensi tersebut, peta jarak antar-topik dipisahkan oleh dua sumbu hasil penskalaan algoritma multidimensi. Kedua sumbu tersebut dapat dihiraukan sebab tidak berarti apa pun. Sementara, ukuran gelembung menggambarkan persentase setiap token (kata yang telah diubah menjadi deret angka) di dalam setiap klaster topik.
Di sebelah kanan, diagram batang bertumpuk menampilkan 30 kata urutan teratas berdasarkan signifikansinya. Ukuran mengenai arti penting ini, yang juga terincikan di bawah diagram, mencerminkan signifikansi suatu istilah. Jika secara ukuran lebih tinggi, maka ia berpengaruh dalam menunjukkan suatu topik tertentu. Setiap kata dalam batang bertumpuk mewakili besaran serta sebaran kata tersebut secara keseluruhan dalam topik yang dipilih maupun kelompok lainnya.
Ketika memilih suatu topik di dalam peta jarak (sebelah kanan) atau menentukan topiknya lewat panel yang berada di atasnya, maka grafik batang bertumpuk akan memperbarui wujudnya dan menampilkan kata-kata paling relevan. Sementara, batang berwarna merah yang berada di atas batang warna biru, menunjukkan frekuensi kemunculan kata tersebut dalam setiap topik yang dipilih di dalam peta. Sedangkan, batang berwarna biru menunjukkan frekuensi kemunculan kata tersebut dalam keseluruhan korpus. Jika warna merah menimpa biru sepenuhnya, maka ia merupakan kata eksklusif dalam topik yang dipilih. Salah satu kata dalam grafik batang yang dipilih akan mengungkapkan topik terkait serta kemungkinan persebarannya dalam peta jarak. Ini memungkinkan kita untuk mengetahui singgungan antara kata dan berbagai topik.

Panel penggeser λ (lambda), yang berada di atas grafik batang bertumpuk, berfungsi untuk menyesuaikan kata-kata yang ditampilkan dalam suatu pengelompokan topik. Jika nilai λ lebih rendah dipilih, maka akan muncul kata-kata dengan frekuensi yang jarang tetapi spesifik untuk topik tertentu. Sedangkan, jika nilai λ yang diaplikasikan lebih tinggi, misalnya mendekati 1, grafik batang akan menunjukkan kata-kata umum dalam korpus yang mungkin tidak terlalu unik untuk topik yang kita pilih. Pencetus LDAvis, Carson Sivert dan Kenneth E. Shirley, menyarankan untuk mengaplikasikan nilai λ sekitar 0,6 untuk mendapatkan interpretasi yang optimal.[4] Akan tetapi, nilai ini tidaklah mutlak. Metrik ini merupakan nilai relatif untuk mengidentifikasi kata yang paling berguna untuk mendeskripsikan atau memahami topik tertentu. Sedangkan semakin tinggi metrik relevansi yang ditunjukkan suatu topik, maka kata tersebut semakin eksklusif untuk topik tersebut. Dengan demikian, grafik interaktif visual LDA akan dapat membantu menentukan parameter interpretasi topik dengan lebih mudah.
Dengan melihat keterkaitan kata-kata yang muncul di atas, tampak begitu sulit untuk menginterpretasikannya tanpa berbekal sedikit pun konteks akan korpus yang diolah. Pemodelan topik dalam kajian sastra seringkali, jika tidak selalu, menjumpai masalah ini pada tahapan awal. Penerapan pemodelan topik dalam eksperimen ini, dengan demikian, kehilangan sesuatu yang fundamental bagi teks sastra.[5]
Masalah Laten dalam Pemodelan LDA
Sebenarnya, pengukuran terhadap nilai koherensi topik dapat mempertajam evaluasi hasil pemodelan.[6] Namun, langkah ini tidak diterapkan dalam eksperimen ini lantaran tahapan ini perlu memaksimalkan kata penghenti, yang idealnya berisi ribuan kata. Untuk mendapatkan hasil maksimal, langkah pembersihan teks perlu diiringi dengan penentuansegmentasinya. Dengan demikian, evaluasi manual akan menentukan luaran yang dihasilkan. Sebagai contoh, eksperimen Inna Uglanova dan Evelyn Gius menunjukkan bahwa keajaiban dari pemodelan topik teks sastra seringkali tidak muncul “jika teks tidak dibersihkan”. Mereka menetapkan setidaknya 1.111 kata penghenti (stopwords) dalam eksperimennya.[7] Namun eksperimen yang dilakukan oleh Rachel Brynsvold dengan korpus Project Gutenberg,[8] yang tidak menerapkan penentuan kata penghenti secara manual dan ketat seperti itu, masih dapat menunjukkan keterbacaan yang dapat diinterpretasi.
Prevalensi kemunculan kata-kata non-substantif yang mendominasi topik memang dapat mengaburkan struktur tematik. Masalah ini menjadi gejala umum dalam kajian-kajian yang memanfaatkan teks sastra.[9] Eksperimen ini juga telah membuktikan bahwa tanpa pembersihan data, hasil ekstraksi topik kurang maksimal meski masih dapat diinterpretasi. Dengan demikian, beragam langkah pembersihan data begitu penting dalam eksperimen pemodelan topik, apalagi pemrosesan teks sastra. Penerapan metode pemodelan topik terhadap diskursus ilmiah atau berita lebih mudah mendapatkan hasil yang bagus hanya dengan membersihkan data dengan sederhana. Hasil yang berbeda dari pemodelan topik kedua jenis tersebut dan teks sastra berpangkal pada struktur teks. Teks-teks ilmiah maupun berita memiliki struktur atau selingkung konvensional yang ideal bagi pemodelan topik. Berbeda dengan teks sastra, yang secara struktur menerapkan fungsi artistik bahasa. Sebagai perangkat statistik, pemodelan topik hanya dapat menunjukkan keumuman maupun ketidaklaziman yang terejawantahkan dalam sebuah bentuk. “Bentuk” dalam hal ini berarti representasi teks sebagai sebuah “kumpulan kata”.
Topik yang diperoleh dalam pemodelan LDA tidak mencerminkan struktur tematik umum dari sebuah teks. Sejalan dengan ini, istilah topik sampai batas tertentu tidak dapat dipahami sebagai sinonim atas “tema” seturut pemahaman formal, tetapi sebagai sebuah metafora terhadap suatu objek dengan kesamaan struktural, fungsi, maupun karakteristik yang dikumpulkan dalam sebuah kelompok yang koheren. Meskipun pemodelan topik korpus novel-novel pemenang DKJ di atas tidak berhubungan secara langsung dengan konten yang terkandung dalam teks sastra lantaran ia tidak menunjukkan arti dari setiap penanda yang diproses, sampai derajat tertentu ia dapat membantu membaca tema laten yang hanya dapat dikenal dan dikelompokkan oleh pembelajaran mesin. Dengan kata lain, pemodelan topik hanya dapat beroperasi pada bentuk dan struktur.
Dari perspektif humanis, evaluasi manusia masih merupakan standar utama dalam mengevaluasi model topik.[10] Interpretasi manual dari topik yang diinterpretasi dari model terdiri dari 10 kata yang menentukan sekitar 30% isi. Dalam hal ini, sepuluh kata per topik menjadi nilai lazim algoritma yang digunakan secara umum. Dari sepuluh kata yang muncul ini, setidaknya terdapat 5 kata yang berhubungan dengan aspek tematis umum.
Yang Laten dan Tak Terbaca oleh Mata
Pertanyaannya kemudian, apa yang disajikan oleh pemodelan topik mengenai struktur tematik atas korpus secara umum? Cerita apa yang dinarasikan antara 1998 – 2021? Topik apa saja yang menarik bagi masyarakat dalam rentang waktu ini? Untuk menjawab pertanyaan ini, dalam bagian ini saya menguraikan pemodelan topik dalam rentang periode 5 tahunan (1998-2002, 2003-2007, 2008-2012, 2013-2017, 2018-2023), untuk memberikan gambaran rinci evolusi tematik dari distribusi topik yang terbaca oleh pemodelan LDA secara visual. Perlu ditekankan bahwa dalam menguraikan interpretasi kualitatif dari kuantifikasi topik pemodelan LDA, saya hanya akan mendeskripsikan hasil yang ditampilkan oleh pembelajaran mesin dan sebisa mungkin berupaya melupakan bagasi informasi mengenai judul-judul novel maupun konteksnya di kepala saya.
Visual Interaktif LDA Novel Pemenang DKJ Periode 1998 – 2002
Topik 1: sultan – riau – belanda – raja – bukit – tidur – kahar – bicara – tangan – hindia – cerita – residen – anak – haji – pikir – dengar – tulis – pandang – hitam – kalimat – suara – singapura – bendera – mata – sadar – pulau – melayu
Klaster pertama dari periode 1998 – 2002 menunjukkan topik tipikal seperti di atas. Dari segmentasi topik pertama, tampak bahwa 10 kata dari klaster pertama berkaitan dengan gagasan nasion, ditunjukkan dengan kedekatan kata-kata yang berkaitan dengan ‘melayu’, ‘kesultanan’, berhadapan dengan misalnya ‘hindia belanda’, ‘singapura’. Dengan demikian, topik pada klaster ini dapat diinterpretasikan sebagai sebuah gagasan kosmopolitanisme, yang menekankan silang-saling budaya yang membentuk cara berpikir dan bertindak suatu masyarakat. Sebab, kemunculan kata-kata yang mengarah pada imajinasi kesejarahan ini berdekatan dengan beberapa kata yang menggambarkan produksi pengetahuan serta mobilisasi, seperti laku ‘menulis’, ‘membaca’, ‘buku’, dan ‘haji’. Jika metrik tersebut diturunkan, kita akan dapat menemukan frekuensi kata yang mengikat semua ini, ‘bangsa’. Meski terdapat suatu token yang unik dengan frekuensi besar, yakni ‘kahar’, yang menjadi petunjuk bahwa terdapat suatu dinamika umum dalam proses ‘globalisasi’ yang ditunjukkan oleh kata kerabatnya yang lain.
Topik 2: lelaki – perempuan – istri – tubuh – teman – rumah – gadis – telepon – jakarta – pemuda – temu – wanita – pria
Topik 3: desa – datuk – bandar – kaya – usaha – lahan – suku – kerja – keluarga – koperasi – camat – adat – tani – kelompok – sungai
Pada klaster selanjutnya, beberapa kata yang tidak relevan tercampur dalam pengelompokan sebab belum sempat terdaftar dalam kata penghenti akan dihiraukan. Namun pada pengelompokan kedua, topik yang muncul tampak ambigu. Mengingat bahwa kohesi maupun koherensi dari setiap topik tercampur, tema yang muncul pada pengelompokan kedua seolah berdiri sendiri, membentuk klaster yang saling berjauhan dengan kelompok pertama dan ketiga. Sedangkan klaster kedua berkisar pada relasi percintaan urban, yang saling dikaitkan dengan kemunculan ‘Jakarta’ sebagai representasi latar dan ‘telepon’ yang pada masa itu masih eksklusif. Berbanding terbalik dengan klaster kedua, topik ketiga berpusar pada penggambaran kehidupan rural serta berkaitan dengan adat, yang ditandai oleh relevansi kata-kata yang menunjukkan pola “kehidupan kolektif” seperti ‘desa’, ‘lahan’, ‘adat’, ‘suku’, dst. Visualisasi hasil analisis LDA novel pemenang DKJ periode 1998 – 2002, sampai batas tertentu, juga menggambarkan kesamaan pola latar tempat serta beberapa konteks kesejarahan yang hadir dalam novel. Latar tempat yang ditunjukkan oleh pengelompokan klaster kata berkisar di Sumatera pedesaan.
Visual Interaktif LDA Novel Pemenang DKJ Periode 2003 – 2007
Topik 1: warna – cinta – gambar – laki-laki – tubuh – malaikat – tinggal – rusia – suka – hidup – ayah – hilang – temu – lukis
Topik 2: glonggong – kiai – kuda –sendang – belanda – jawa – sendang – sultan
Topik 3: pesantren – arab – perempuan – yahudi – ustaz – santri – laki-laki – prahara – jin
Periode 2003 – 2007, menunjukkan keunikan tersendiri. Dua klaster topik yang saling beririsan, memiliki keterhubungan yang berkisar pada persoalan cinta dan pertemuan. Meski menunjukkan relevansi yang jelas, keterbacaan pola topik yang terkelompokkan dalam periode ini sulit dikategorisasikan secara spesifik, mengingat kata-kata yang muncul terlalu spesifik atau bahkan sangat umum. Oleh karena itu, keketatan metode yang telah saya tetapkan, yakni hanya berfokus menjabarkan hasil pembacaan mesin, terpaksa saya tabrak. Saya menengok singkat konteks novel-novel dari periode ini. Ternyata, kemunculan kata yang relevansinya merujuk pada gender maupun tubuh dalam klaster pertama periode ini, serupa dengan periode sebelumnya yang mungkin terpengaruh oleh novel Saman (1998) karya Ayu Utami, yang sampai batas tertentu jauh dari nilai heteronormatif. Pola ini kemungkinan besar terpengaruhi novel Tabula Rasa (2004) karya Ratih Kumala. Sementara, frekuensi kata lain dari periode ini yang saling bersinggungan mengarahkan pada tema sureal.
Kesamaan relevansi topik dengan periode sebelumnya terletak pada klaster kedua, yang berisi kata ‘Belanda’. Kemunculan kata ‘Belanda’ yang berdekatan dengan beberapa kata yang memiliki relevansi dengan budaya Islam dalam hal ini juga berkaitan dengan klaster topik pertama periode 1998 – 2002. Kedua topik yang bersinggungan dari dua periode ini memang tidak menunjukkan secara pasti inti narasi dari frekuensi kata-kata yang bersinggungan tersebut, tetapi menarik bahwa keduanya memiliki pola yang mirip. Ini menunjukkan bahwa algoritma mengelompokkan pembicaraan konteks kesejarahan kolonial dengan peradaban Islam. Akan tetapi, klaster ini begitu berjauhan dengan misalnya klaster pertama dan ketiga yang memiliki keterikatan kuat lantaran terhubung dengan pembicaraan soal cinta. Maka, dapat ditebak, bahwa terdapat suatu pembicaraan khusus dari periode ini yang membicarakan sejarah, sementara yang lain tengah membicarakan persoalan yang berkaitan dengan cinta. Sementara, klaster ketiga berkisar pada kehidupan serta budaya Islam, mengingat relevansi kata menunjukkan kedekatan dengan hal-hal yang berkaitan dengan ‘santri’, ‘pesantren’, ‘ustaz’, ‘jin’.
Visual Interaktif LDA Novel Pemenang DKJ Periode 2008 – 2012
Topik 1: Hewan – sapi – babi – burung – dokter – sakit – lelaki – ternak
Topik 2: Kapau – lanun – panglima – datuk – kaya – tuan – pace – jantan – perang
Topik 3: Tentara – kampung – prajurit – serdadu – senjata – berontak – liar – lelaki – kaum – pos
Tema unik yang dari periode ini, seperti yang ditunjukkan dari frekuensi kata dalam kelompok pertama, berkisar pada persoalan peternakan dan kesehatan. Sedangkan, prevalensi topik yang muncul dalam klaster kedua dan ketiga berkisar pada konflik di daerah pesisir, lebih tepatnya di Aceh, yang ditunjukkan dengan kemunculan kata ‘lanun’. Relevansi topik ini juga ditunjukkan dengan beberapa rentetan kata ‘tentara’, ‘prajurit’, ‘serdadu’, ‘senjata’, ‘berontak’. Sebagai ilustrasi, jika salah satu dari kata tersebut dipilih (ingat untuk menggeser nilai λ sampai 0.6), maka ia akan menunjukkan frekuensi yang begitu besar, ditandai dengan pemekaran ukuran gelembung. Selain itu, yang membuat kedua topik ini beririsan bukan hanya persoalan di Sumatera tetapi Papua, yang ditunjukkan dengan beberapa kata maupun istilah Papua. Keduanya topik ini saling menunjukkan soal lanskap dari data korpus yang menunjukkan kedua wilayah yang sangat berseberangan ini. Pengelompokan ini, baik dalam kluster pertama dan kedua yang saling beririsan, yang berisi kata-kata yang berkaitan dengan kehidupan pedesaan, juga memperlihatkan keterkaitan tema kehidupan rural agraris maupun pesisir.
Visual Interaktif LDA Novel Pemenang DKJ Periode 2013 – 2017
Topik 1: cinta – perempuan – bumi – pohon – keluarga – kaum – tubuh – cerita – adat – kota – tanah – langit – bunuh – uang – rusuh
Topik 2 : kambing – partai – buku – hujan – kamar – shalat – rusun – guru – surat – suara – desa – sekolah – aceh –mushalla – kampung
Topik 3: jawa – sultan – cerita – kuda – keraton – kiai – raden – belanda – edinburgh – wilayah – kasultanan – bunuh – kuasa
Korpus periode 2013 – 2017 sebenarnya memiliki keragaman menarik yang temanya merentang mulai dari realisme magis hingga fiksi ilmiah, diwakili oleh novel Faisal Oddang, Puya ke Puya (2015) atau Sabda Armandio, 24 Jam Bersama Gaspar (2017). Tren ini terbaca misalnya dalam kata ‘detektif’ yang berkaitan dengan ‘pembunuhan’, lema yang muncul pada klaster pertama sempat muncul sebelum saya menentukan beberapa penghentian kata tambahan untuk mendapatkan koherensi maksimal. Namun, seperti yang telah disinggung, algoritma LDA tidak dapat membaca keragaman serta kekhasan sastrawi dari korpus ini. Keterbatasan ini tercermin secara jelas dari klaster pertama yang sampai batas tertentu hanya menangkap tema umum dari keseluruhan korpus, yang berkisar pada kompleksitas kehidupan dengan frekuensi utama pada persoalan cinta. Relevansi kata yang mengikutinya, seperti ‘adat’, ‘kota’, dan seterusnya tidak menunjukkan korelasi yang dapat ditangkap secara spesifik. Sementara klaster kedua, secara spesifik berkaitan dengan kehidupan pesantren. Begitu pula dengan pengelompokan ketiga yang menunjukkan relevansi dengan tema kesejarahan, dalam hal ini Kesultanan Yogyakarta dan masa kolonial Belanda.
Visual Interaktif LDA Novel Pemenang DKJ Periode 2018 – 2021
Topik 1: kereta – hidup – orang-orang – mati – manusia – zaman – dunia – stasiun – belanda – gembala
Topik 2: kumbang – burung – angsa – istri – jelita – gendut – wajah – laut – balada – sinar – anak
Topik 3: makan – berat – latih – pacar – laki-laki – badan – nutrisi – komentar – sehat – diet – program – hidup – perempuan – tubuh – apartemen – pribadi – hasil – tidur – target – sakit
Dua topik dominan yang dibicarakan dari periode paling mutakhir ini ialah soal perjalanan melintasi ruang waktu (diwakili klaster pertama) dan soal program menurunkan berat badan (yang diwakili klaster ketiga dan beririsan dengan klaster kedua). Relevansi frekuensi kata yang muncul pada topik pertama dari pengelompokan periode ini mengarah pada soal keterkaitan sejarah masa kolonial. Sedangkan klaster ketiga, seperti yang telah terstruktur secara runtut, menunjukkan tema kesehatan, khususnya program diet.
Uraian secara periodik hasil pemodelan topik di atas dapat diringkas sebagai berikut. Pertama, terdapat kesamaan mencolok mengenai konteks kesejarahan yang disisipkan atau diceritakan ulang. Dalam pengelompokan terakhir, kata ‘Belanda’ misalnya, berada pada klaster utama. Keterkaitan soal tema sejarah kolonialisme ini mulai tampak jelas sejak periode 2003 – 2007. Jika kembali pada visual interaktif periode itu, kata ‘Belanda’ menunjukkan keterhubungan yang kuat dengan dua pengelompokan topik lainnya. Aspek kesejarahan lainnya meliputi sejarah kesultanan di Jawa maupun Sumatera, yang juga beririsan dengan masa kolonialisme. Pembicaraan mengenai konteks kesejarahan sejak 2003, selalu mewarnai setiap periode selanjutnya. Tercatat bahwa dalam setiap periode pembicaraan sejarah selalu hadir dengan keunikan persoalannya, semisal secara spesifik yang berkaitan dengan sejarah peradaban Islam maupun konflik–topik yang juga sering muncul. Dengan demikian, selama dua dekade ke belakang, konteks sejarah selalu identik dengan novel-novel pemenang sayembara DKJ.
Kedua, topik gender menjadi pembicaraan yang menonjol sejak periode 1998 – 2002. Akan tetapi, yang menarik, pembacaan konteks perlu dilakukan khususnya untuk tema ini lantaran mesin tidak dapat mengidentifikasi hubungan yang ditunjukkan oleh kata-kata yang memiliki relevansi terhadap topik gender. Meski sampai batas tertentu, kemunculan serta frekuensi kata yang mengikuti ‘tubuh’ dan ‘seks’ memang tidak biner, dan menunjukkan adanya keunikan tersendiri dalam pengelompokan ini. Namun tetap saja mesin tidak mampu mengidentifikasi nilai yang jauh dari heteronormatif, dalam hal ini homoseksual. Pembicaraan topik gender masih menjadi arus utama hingga 2007. Dalam periode selanjutnya ia tetap muncul tetapi beririsan dengan keragaman pembicaraan topik lainnya. Tema lain yang selalu seiring atau berkait kelindan dengan topik gender adalah cinta. Topik mengenai cinta, muncul secara dominan sejak awal dan menjadi semakin menonjol pada periode 2013 – 2017.
Ketiga, persoalan adat serta penggambaran masyarakat rural juga konsisten muncul sejak 1998. Kemunculan tema ini ditandai dengan frekuensi pengelompokan yang merujuk pada cara, laku hidup masyarakat atau bahkan secara spesifik menunjukkan latar cerita yang seringkali muncul di dalam korpus. Selain itu, meski tidak dapat disandingkan secara sejajar, pembicaraan adat juga menjadi topik dominan. Ia muncul sejak 1998, dan kemudian periode 2013 – 2017 juga menandai ulang kemunculan topik pembicaraan ini secara dominan. Akan tetapi perlu dicatat, bahwa tema kehidupan pedesaan maupun adat, yang muncul biasanya seringkali tumpang-tindih, mengingat relevansi kata yang merujuk pada kedua tema ini seringkali identik. Akan tetapi, kontras dengan dua tema ini, tema kehidupan urban juga sering muncul sejak 1998. Namun, kemungkinan besar secara perbandingan, kemunculan topik rural maupun adat mudah diidentifikasi karena keunikannya, berbeda dengan topik urban yang mungkin tercampur dengan konteks lain.
Perlu dicatat pula, pengelompokan unik lainnya, yang tidak tervisualisasikan lantaran sudah dibuang, ialah kemunculan begitu banyak kata-kata lokal. Kata-kata tersebut umumnya berasal dari bahasa Aceh, Bugis, Jawa, dll. Kemunculan bahasa lokal dalam pengelompokan ini juga menandai bahwa dalam periode 25 tahun sejak 1998, keterkaitan umum antara novel-novel pemenang sayembara ialah penyerapan bahasa lokal. Semua kata dari bahasa daerah dibuang lantaran mesin tidak mengenalinya sebagai bahasa Indonesia, dan mayoritas kata tersebut belum terserap dalam modul yang dipakai. Di sisi lain, kata-kata dari bahasa asing, misalnya bahasa Inggris, juga membentuk pengelompokan tersendiri. Meski menjadi kelompok yang terasing tersendiri, beberapa nama tempat seperti Kremlin ataupun Moskow muncul bersamaan dalam himpunan ini.
Terakhir, kelompok tematik yang paling menonjol karena keunikannya adalah tema kesehatan. Topik yang muncul sejak periode 2008 ini tidak terbatas pada kesehatan manusia, tetapi juga hewan. Sedangkan, periode mutakhir menunjukkan bahwa pembicaraan mengenai topik ini berkisar pada persoalan diet. Sebagaimana yang telah diuraikan, semua kecenderungan umum ini mewakili keberagaman serta evolusi tematik dalam sayembara novel DKJ. Dapat disimpulkan dalam dua dekade lebih belakangan, tema pemenang novel diwarnai dengan keberagaman gender, cara hidup masyarakat, serta seringkali menyisipkan konteks kesejarahan lokal maupun masa kolonial. Sayang, tidak ada pembanding yang bisa membuktikan bahwa kecenderungan ini memang muncul sekitar dua dasawarsa terakhir. Penelitian lebih lebih lanjut yang lebih komprehensif, yang juga menganalisis pemenang sayembara novel dari 1974 hingga 1998, saya kira, dapat memberikan gambaran apakah memang kecenderungan ini merupakan keunikan tersendiri dari novel-novel pemenang pasca-1998.
Dengan mengandaikan bahwa saya tidak membaca sama sekali konten maupun konteks keseluruhan dari novel yang dianalisis, kelima klaster tersebut menunjukkan pola umum model topik novel-novel pemenang sayembara DKJ selama 25 tahun ke belakang. Dengan demikian, pemrosesan bahasa alami yang mengandalkan stilistika korpus ini dapat dipahami dengan melihat makna sebuah kata dari seluruh konteks kemunculannya, atau mengutip Martin Suryajaya,[11] “himpunan semua ekstensinya di sembarang dunia-mungkin”.
Susunan yang topik yang dibentuk oleh penskalaan algoritma multidimensional dalam analisis dengan LDA ini tidak sekadar membantu mengelompokkan topik dari frekuensi kemunculan setiap kata dengan kerabatnya, yang kemudian dapat diinterpretasikan. Lebih dari itu, ia memperlihatkan suatu pola umum tak kasat mata, yang tidak akan terlihat dengan metode pembacaan formal. Dalam hal ini, misalnya, saya dapat mengajukan pendapat bahwa novel-novel pemenang sayembara DKJ pasca-1998 mencoba membicarakan persoalan kesejarahan kolonialisme. Meskipun kedekatan kata-kata ini menunjukkan adanya kesadaran itu, bukan berarti dengan demikian pembicaraan kolonialisme itu tidak terlepas dari bias. Sebab data yang ditunjukkan oleh LDA hanya mampu menunjukkan apa saja yang sering dibicarakan secara beririsan dalam rentang waktu tersebut.
Hasil pembacaan jauh ini, meski hanya memetakan topik, dalam hal ini dapat membantu mengurai lebih jauh kecenderungan maupun pola umum, sebuah tugas yang tidak dapat diselesaikan oleh ChatGPT-4 yang dikembangkan oleh OpenAI. Akan tetapi, saya meninggalkan sebuah catatan penting dalam analisis serupa ini: perlu diingat bahwa humaniora digital bukanlah pendekatan yang dapat diakses semua orang. Kenyataan pra-pemrosesan data dan sulitnya mengumpulkan akses sumber, menyadarkan saya bahwa ini bukan hanya kerja kolosal, tetapi juga tidak murah. Dalam tahap pemindaian saja, laptop dengan kekuatan kartu grafis ala kadarnya tidak mampu memproses teks yang telah dipindai menjadi teks yang siap untuk diolah. Begitu pula ketika merangkai kode.
[1] Sebagai konteks kajian komputasi sastra yang menerapkan AI ataupun Large Language Model lihat Hatzel, H., Stiemer, H., Biemann, C. & Gius, E. (2023). “Machine learning in computational literary studies.” it – Information Technology, 65(4-5), hlm. 200-217
[2] Beberapa contoh kajian yang menerapkan teknik komputasional dalam kajian sastra antara lain, M. L. Jockers & D. Mimno. (2013) “Significant themes in 19th-century literature” dalam Poetics, Vol 41, No. 6, hlm. 750–769; C. Schöch. (2017) “Topic Modeling Genre: An Exploration of French Classical and Enlightenment Drama” dalam Digital Humanities Quarterly Vol 11, No. 2; Simon Päpcke, Thomas Weitin dkk. (2023) “Stylometric similarity in literary corpora: Non-authorship clustering and Deutscher Novellenschatz” dalam Digital Scholarship in the Humanities, Vol 38, No. 1.
[3] Saya mengucapkan terima kasih sedalam-dalamnya kepada Robby Bouce Garnia yang telah membantu proses pemindaian serta kepada Martin Suryajaya, Dewi Kharisma Michellia, dan Zen Hae yang telah meminjamkan beberapa koleksi pribadinya serta membantu proses penulisan ini sejak awal.
[4] Carson Sivert dan Kenneth E. Shirley. (2014). “LDAvis: A method for visualizing and interpreting topics.” dalam Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces. hlm. 67
[5] Kritik terhadap pendekatan komputasi sastra sebenarnya telah disampaikan oleh banyak peneliti, lihat misalnya artikel Nan Z. Da (2019) yang terbit dalam Critical Inquiry, “The Computational Case against Computational Literary Studies”.
[6] Uglanova, I, & Gius, E. (2020). “The Order of Things. A Study on Topic Modelling of Literary Texts” dalam Workshop on Computational Humanities Research.
[7] Ibid. hlm. 60
[8] Rachel Brynsvold. (2017) “Literary Analysis via NLP: Topic Modeling Project Gutenberg” https://pyvideo.org/pytexas-2017/literary-analysis-via-nlp-topic-modeling-project-gutenberg.html
[9] Lihat misalnya, M. Jockers. 2013. “Secret” Recipe for Topic Modeling Themes.” https://www.matthewjockers.net/2013/04/12/secret-recipe-for-topic-modeling-themes/; T. Underwood. 2012. “What kinds of “topics” does topic modeling actually produce?” https://tedunderwood.com/2012/04/01/what-kinds-of-topics-does-topic-modeling-actually-produce/
[10] J. Chang dkk. “Reading Tea Leaves: How Humans Interpret Topic Models” dalam NIPS. (Ed.) Y. Bengio et al. Curran Associates, Inc., 2009, hlm. 288–296
[11] Suryajaya, Martin. 2022. “Seni sebagai Pelarian ke dalam Kepribadian Lain: Sebuah Eksperimen Pembacaan Jauh atas Dua Marga” dalam Jurnal Urban Vo. 6, No. 1.